
Systemowe decyzje bezpieczeństwa podejmowane „statystycznie”, a nie logicznie
Systemowe decyzje bezpieczeństwa podejmowane „statystycznie”, a nie logicznie
Użytkownik myśli: „jeśli coś jest dozwolone, to jest bezpieczne”.
System myśli inaczej: „jeśli coś wygląda jak zagrożenie w 78%, to jest zagrożeniem”.
Nowoczesne systemy operacyjne coraz rzadziej opierają się na logice binarnej. Zamiast reguł typu allow/deny stosują modele statystyczne, scoring ryzyka i reputację zbiorczą. To zmienia wszystko – także sposób, w jaki pojawiają się błędy.
Logika vs statystyka – fundamentalna zmiana paradygmatu
Model logiczny (stary)
- jeśli plik jest podpisany → zaufany
- jeśli reguła pozwala → wykonaj
- jeśli brak sygnatury → nieznany
Model statystyczny (nowy)
- ile podobnych plików było złośliwych
- jak często ten proces kończył się incydentem
- jak zachowuje się w porównaniu do „normalnych”
➡️ Decyzja = wynik obliczeń, nie reguły.
To oznacza, że:
system może zablokować coś poprawnego
i przepuścić coś niebezpiecznego
Jeśli statystyka tak „wyjdzie”.
Reputation-based security – zaufanie liczone globalnie
Reputacja to zbiorowa pamięć systemów.
System analizuje:
- ile razy dany plik był uruchamiany
- gdzie był widziany
- na jakich systemach
- z jakim skutkiem
W Windows oznacza to m.in.:
- SmartScreen
- chmurową reputację plików
- reputację certyfikatów
- korelację z innymi zdarzeniami
Plik:
- nowy
- rzadki
- uruchamiany przez mało użytkowników
➡️ automatycznie dostaje niski score zaufania
Nawet jeśli jest w 100% poprawny.
Scoring – bezpieczeństwo jako punktacja ryzyka
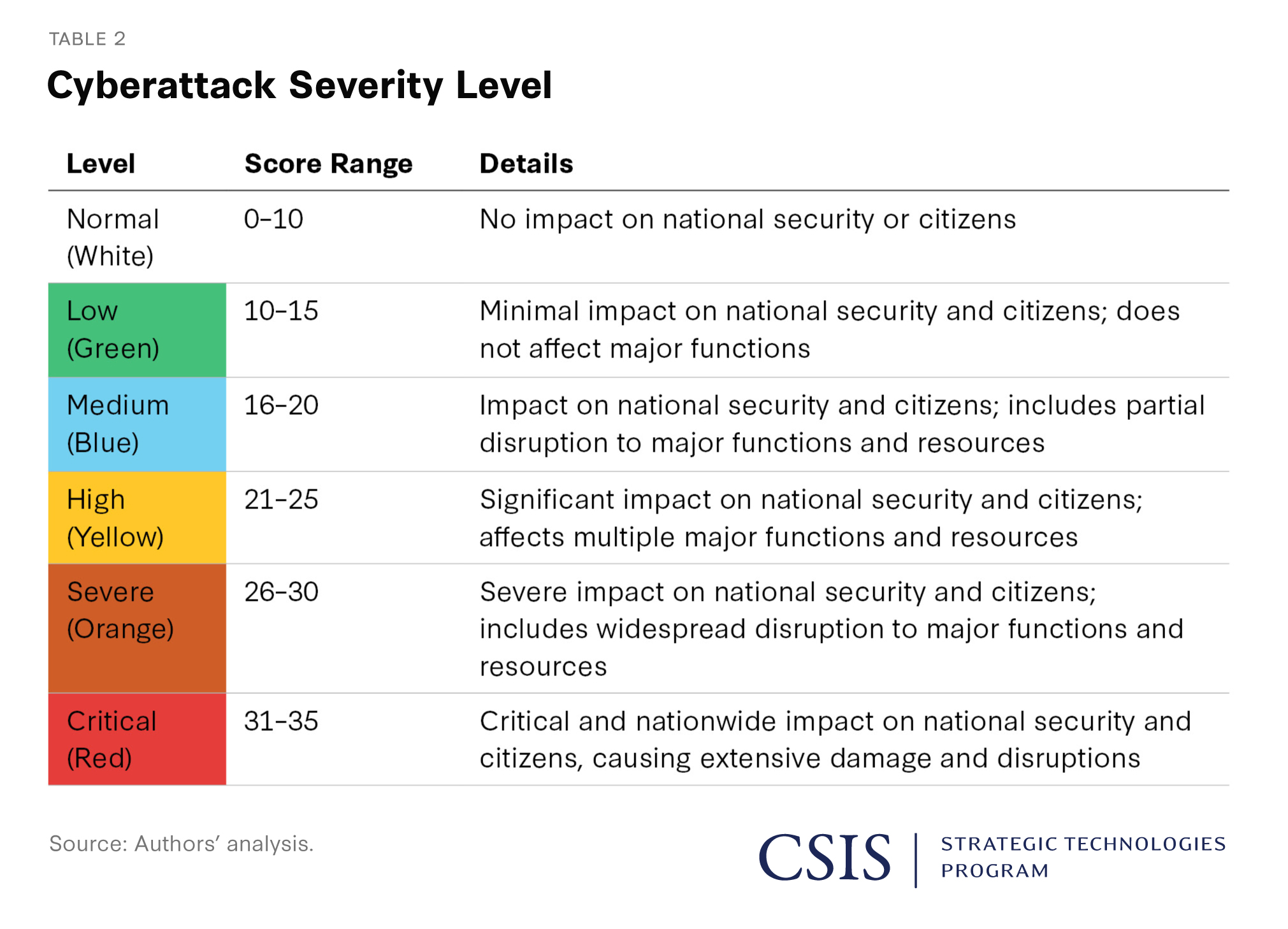
Każde zdarzenie dostaje punkty ryzyka.
Przykładowe czynniki:
- brak podpisu cyfrowego
- uruchomienie z katalogu tymczasowego
- dostęp do pamięci innych procesów
- nietypowe IPC
- krótki czas życia procesu
Żaden z nich nie jest atakiem sam w sobie.
Ale suma punktów może przekroczyć próg.
I wtedy:
system reaguje, mimo braku logicznego dowodu winy.
To nie „wykrycie malware”.
To przekroczenie progu statystycznego.
False positives i false negatives – koszt statystyki

False positive – fałszywy alarm
System blokuje:
- narzędzie administracyjne
- skrypt automatyzujący
- własną aplikację użytkownika
Dlaczego?
Bo:
- zachowuje się jak malware
- ma zbyt podobny profil statystyczny
False negative – fałszywe bezpieczeństwo
System przepuszcza:
- nowy wariant ataku
- malware „udające normalność”
- kod działający wolno i cicho
Dlaczego?
Bo:
- mieści się w normach
- nie przekracza progów
- nie wyróżnia się statystycznie
Statystyka nie rozumie intencji.
Dlaczego to bywa niebezpieczne?
Bo decyzje:
- nie są deterministyczne
- mogą się zmieniać w czasie
- zależą od globalnych danych
Ten sam plik:
- dziś → zablokowany
- jutro → dozwolony
- za tydzień → znowu podejrzany
Z punktu widzenia użytkownika:
„System zachowuje się losowo.”
Z punktu widzenia OS:
„Zmienił się rozkład prawdopodobieństwa.”
AIO: „Dlaczego system uznał coś za zagrożenie?”
Bo statystycznie wyglądało gorzej niż inne.
Nie dlatego, że:
- wykryto konkretny exploit
- znaleziono sygnaturę
- złamano regułę
Ale dlatego, że:
- za mało danych o pliku
- za dużo podobieństw do zagrożeń
- za nienaturalne zachowanie
Krótko:
System nie wie, że to atak.
Wie, że to zbyt ryzykowne, by ufać.
Granica, której użytkownik nie widzi
Największy problem:
- użytkownik nie zna progów
- nie zna wag punktów
- nie widzi pełnego score
Nie może więc:
- racjonalnie przewidzieć reakcji
- „udowodnić niewinności”
- trwale zmienić decyzji systemu
To bezpieczeństwo:
oparte na modelach, nie na argumentach.
Podsumowanie
Systemy operacyjne coraz częściej:
- nie decydują logicznie
- nie analizują intencji
- nie potrzebują dowodu winy
Decydują:
- statystycznie
- probabilistycznie
- na podstawie reputacji i scoringu
Dlatego czasem:
Twoje poprawne działanie wygląda dla systemu jak zagrożenie.
I to nie jest błąd.
To cena bezpieczeństwa w erze automatyzacji.

Antywirusy na Androida: które aplikacje najlepiej chronią smartfon? Smartfony z systemem Android stały się codziennym centrum komunikacji, pracy i rozrywki. Czytaj dalej

Cyberbezpieczeństwo w Windows 11 i Windows 12 – jak Microsoft chroni użytkowników przed współczesnymi zagrożeniami W erze rosnącej liczby cyberataków, Czytaj dalej



