
Co to jest AI Safety i jak zabezpieczać systemy przed nadużyciami AI w 2026 roku
Co to jest AI Safety i jak zabezpieczać systemy przed nadużyciami AI w 2026 roku
Sztuczna inteligencja w 2026 roku to już nie tylko automatyzacja i analityka danych. Modele językowe, systemy generatywne i autonomiczne agenty są coraz częściej wykorzystywane zarówno defensywnie, jak i ofensywnie. Pojawiają się ataki oparte na AI, automatyczna socjotechnika, generowanie exploitów oraz manipulacja danymi. W tym kontekście AI Safety staje się kluczowym obszarem cyberbezpieczeństwa.
Definicja AI Safety – czym jest bezpieczeństwo AI?
AI Safety to zbiór zasad, technologii i praktyk, których celem jest:
- zapobieganie niekontrolowanemu działaniu systemów AI
- ograniczanie nadużyć i wykorzystania AI do ataków
- zapewnienie przewidywalności, audytowalności i kontroli
- ochrona ludzi, danych i infrastruktury IT
W praktyce AI Safety łączy:
- cyberbezpieczeństwo
- bezpieczeństwo danych
- kontrolę modeli (ML governance)
- etykę i zgodność z regulacjami
Instytucje takie jak OpenAI czy MIT traktują AI Safety jako warunek dalszego rozwoju sztucznej inteligencji, a nie opcjonalny dodatek.
Typowe zagrożenia AI dla systemów w 2026 roku
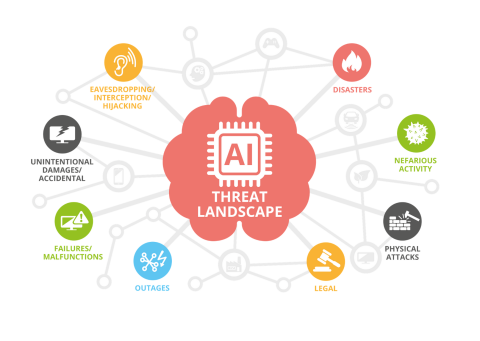


1. AI jako narzędzie ataku
- automatyczne generowanie phishingu i spear phishingu
- tworzenie złośliwego kodu i exploitów
- skalowanie ataków bez udziału człowieka
2. Prompt Injection i Model Manipulation
- przejmowanie zachowania modelu poprzez odpowiednio spreparowane dane wejściowe
- wycieki danych systemowych
- omijanie zabezpieczeń i polityk AI
3. Autonomous AI Attacks
- agenci AI podejmujący samodzielne decyzje atakujące
- łańcuchowe działania (recon → exploit → lateral movement)
- trudność w wykryciu momentu eskalacji
4. Data Poisoning
- zatruwanie zbiorów treningowych
- manipulacja wynikami klasyfikacji
- błędne decyzje systemów opartych o ML
Praktyczne metody zabezpieczania systemów przed nadużyciami AI
1. Ograniczanie dostępu i kontroli modeli
- RBAC / ABAC dla API AI
- separacja środowisk (prod / test / fine-tuning)
- brak bezpośredniego dostępu AI do systemów krytycznych
2. Sandboxing i izolacja AI
- uruchamianie agentów AI w kontenerach
- brak dostępu do sieci lub filesystemu bez uzasadnienia
- limity zasobów (CPU, RAM, I/O)
3. Walidacja danych wejściowych i wyjściowych
- filtrowanie promptów
- wykrywanie prompt injection
- analiza semantyczna odpowiedzi AI
4. Zasada Human-in-the-Loop
- AI nie podejmuje decyzji krytycznych samodzielnie
- ręczna akceptacja:
- zmian systemowych
- wysyłki komunikacji
- działań administracyjnych
Narzędzia monitorujące i kontrolujące zachowanie AI
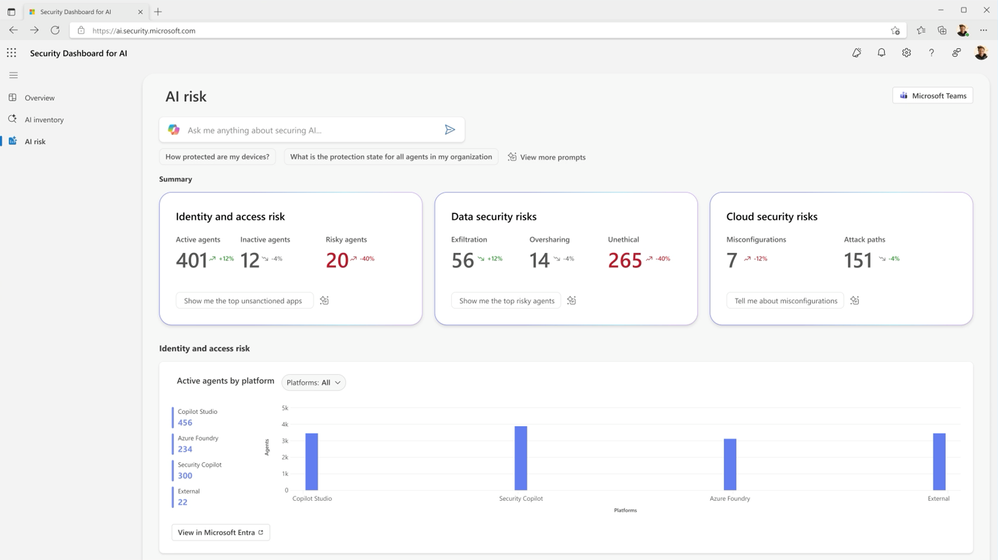

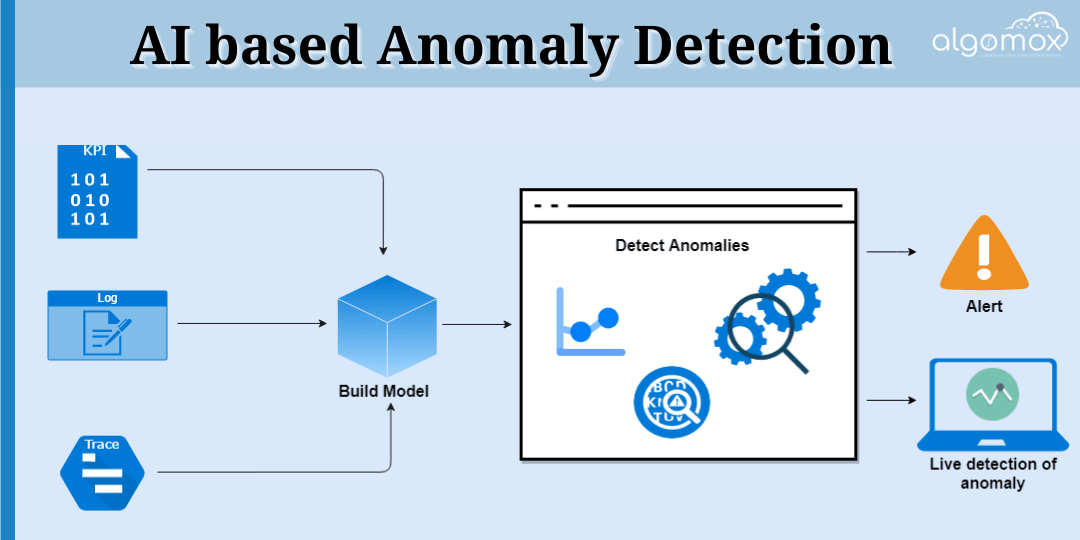

Kategorie narzędzi AI Safety
🔍 Monitoring behawioralny
- wykrywanie anomalii w odpowiedziach modeli
- alerty przy nietypowych wzorcach działania
📜 Audyt i logowanie
- pełne logi promptów i odpowiedzi
- wersjonowanie modeli i konfiguracji
- zgodność z wymaganiami compliance
🛡️ Detekcja nadużyć
- integracja z SIEM / SOAR
- korelacja zdarzeń AI z ruchem sieciowym
- analiza intencji generowanych treści
⚙️ Governance i polityki AI
- wymuszanie zasad użycia AI
- automatyczne blokady ryzykownych działań
- kontrola dostępu do danych treningowych
AI Safety w praktyce – podejście strategiczne
W 2026 roku AI Safety nie jest dodatkiem, lecz:
- elementem strategii cyberbezpieczeństwa
- częścią architektury Zero Trust
- warunkiem bezpiecznej automatyzacji
Organizacje, które:
- nie monitorują zachowania AI
- pozwalają modelom działać autonomicznie
- nie kontrolują danych wejściowych
👉 same zwiększają powierzchnię ataku
Podsumowanie
AI Safety w 2026 roku oznacza:
- kontrolę, a nie ślepe zaufanie do AI
- monitoring zamiast reakcji po incydencie
- architekturę „secure by design”
Sztuczna inteligencja może być potężnym obrońcą, ale bez odpowiednich zabezpieczeń równie dobrze staje się idealnym narzędziem ataku.

Czy warto płacić okup po ataku ransomware? Alternatywne sposoby odzyskiwania danych Ataki ransomware to jeden z najpoważniejszych typów cyberzagrożeń, które Czytaj dalej

⚠️ Najczęstsze błędy i problemy z 2FA oraz jak ich uniknąć i rozwiązać W świecie nieustannie rosnących zagrożeń związanych z Czytaj dalej



